
처음 무중단 배포라는 말을 들었을 때는 조금 거창하게 느껴졌다.
서비스를 끊지 않고 배포한다는 말은 쉬운데, 막상 생각해보면 애매한 부분이 많다.
서버를 재시작해야 하는데 사용자는 계속 요청을 보내고 있고, 그 요청이 어느 서버로 가는지도 생각해야 한다.
배포 중인 서버로 요청이 들어가면 에러가 날 수도 있고, 반대로 너무 빨리 서버를 내리면 처리 중이던 요청이 끊길 수도 있다.
그래서 중간에 트래픽을 조절해주는 무언가가 필요하다.
그 역할을 하는 대표적인 도구 중 하나가 HAProxy다.
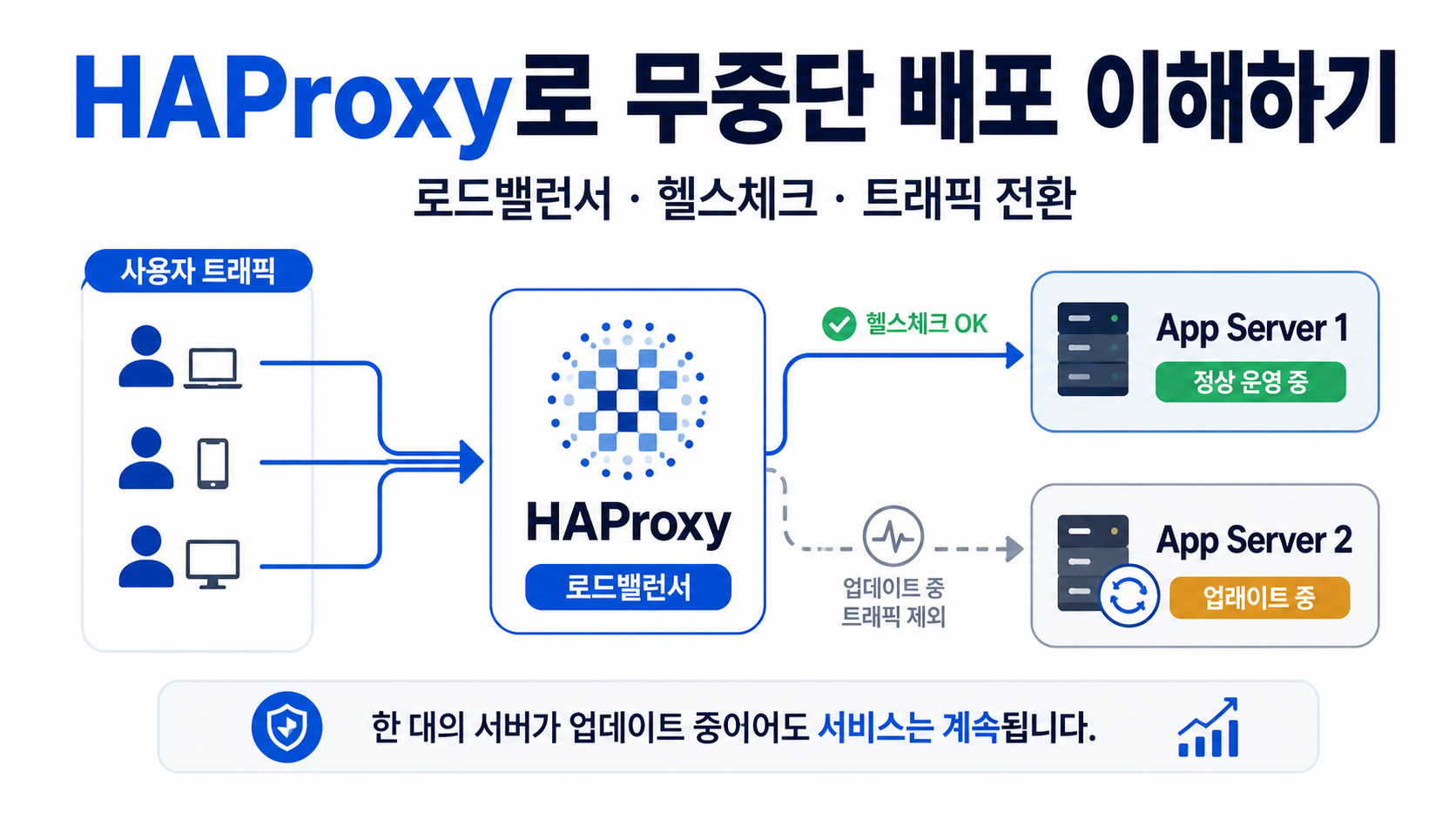
HAProxy는 TCP/HTTP 요청을 여러 서버로 나눠 보내는 로드밸런서이자 리버스 프록시로 많이 사용된다.
공식 사이트에서도 HAProxy를 TCP와 HTTP 기반 애플리케이션을 위한 빠르고 안정적인 reverse proxy, load balancer라고 설명하고 있다.
처음에는 그냥 “요청을 여러 서버로 나눠주는 도구” 정도로만 생각했다.
그런데 무중단 배포를 생각하기 시작하면 HAProxy의 역할이 조금 더 분명해진다.
예를 들어 앱 서버가 두 대 있다고 해보자.
Client
|
HAProxy
|
|-- app-01
|-- app-02평소에는 HAProxy가 app-01, app-02로 요청을 나눠 보낸다.
그러다가 새 버전을 배포해야 한다면 한 번에 두 서버를 다 내리면 안 된다.
그러면 그 순간 받을 서버가 없어지니까 서비스가 끊긴다.
그래서 보통은 한 대씩 배포한다.
먼저 app-01을 트래픽 대상에서 빼고, app-02만 요청을 받게 한다.
그다음 app-01에 새 버전을 배포하고 정상인지 확인한다.
문제가 없으면 다시 app-01을 트래픽 대상에 넣고, 이번에는 app-02를 빼서 배포한다.
흐름만 보면 단순하다.
1. app-01 트래픽 제외
2. app-01 배포
3. app-01 헬스체크 확인
4. app-01 트래픽 복귀
5. app-02 트래픽 제외
6. app-02 배포
7. app-02 헬스체크 확인
8. app-02 트래픽 복귀이게 무중단 배포의 기본적인 감각에 가깝다.
서버를 아예 안 끄는 게 아니라, 사용자가 체감하지 않도록 순서를 잘 나누는 방식이다.
여기서 중요한 게 헬스체크다.
HAProxy는 backend 서버가 정상인지 확인할 수 있다.
헬스체크를 통해 정상 서버만 로드밸런싱 대상에 남기고, 문제가 있는 서버는 요청 대상에서 제외할 수 있다. HAProxy 공식 문서에서도 health check는 정상 서버만 로드밸런싱 rotation에 유지하기 위한 기능으로 설명한다.
예를 들면 이런 식이다.
backend app_backend
balance roundrobin
option httpchk GET /health
server app01 10.0.0.11:8080 check
server app02 10.0.0.12:8080 check여기서 check가 붙은 서버들은 HAProxy가 상태를 확인한다.
/health 요청이 정상 응답을 주면 트래픽을 보내고, 실패하면 제외한다.
배포를 생각하면 꽤 중요한 부분이다.
새 버전을 올렸는데 애플리케이션은 실행됐지만 DB 연결이 안 될 수도 있다.
프로세스는 떠 있는데 내부적으로 필요한 설정값이 빠져 있을 수도 있다.
단순히 포트가 열렸는지만 보는 헬스체크라면 이런 문제를 놓칠 수 있다.
그래서 /health를 어떻게 만들지도 생각해야 한다.
너무 깊게 검사하면 헬스체크 자체가 부담이 될 수 있고, 너무 얕게 검사하면 실제 장애를 못 잡는다.
이 균형이 생각보다 애매하다.
그리고 무중단 배포에서 자주 나오는 개념이 drain이다.
서버를 바로 죽이는 게 아니라, 새 요청은 더 이상 받지 않게 하고 기존 요청은 마무리하도록 기다리는 방식이다.
HAProxy에서는 런타임 API를 통해 서버 상태를 drain으로 바꾸는 방식도 사용할 수 있다. drain은 새 요청을 막고 기존 연결이 끝나도록 기다리는 배포 흐름에서 자주 언급된다.
느낌은 이렇다.
app-01을 바로 종료하지 않는다.
1. app-01로 새 요청이 가지 않게 한다.
2. 이미 처리 중인 요청이 끝나길 기다린다.
3. 연결 수가 줄어든 뒤 배포한다.단순 API 서버라면 금방 끝날 수 있다.
하지만 파일 업로드, 긴 요청, WebSocket 같은 게 있으면 얘기가 달라진다.
특히 WebSocket은 연결이 오래 유지되기 때문에 “그냥 서버 한 대 빼고 배포하면 되겠지” 하고 접근하면 생각보다 꼬일 수 있다.
무중단 배포를 구성할 때 내가 헷갈렸던 부분도 여기였다.
처음에는 Blue/Green 배포랑 HAProxy 전환 방식이 거의 같은 말처럼 느껴졌다.
둘 다 트래픽을 다른 쪽으로 넘기는 느낌이니까.
그런데 조금 다르게 보면 이해가 쉽다.
Blue/Green은 배포 전략에 가깝다.
현재 운영 중인 환경을 Blue라고 하고, 새 버전을 Green에 미리 올려둔다.
그리고 준비가 끝나면 트래픽을 Green으로 넘긴다.
반면 HAProxy는 그 전환을 실제로 수행해주는 도구 중 하나다.
Blue/Green = 배포 전략
HAProxy = 트래픽을 넘겨주는 프록시/로드밸런서물론 HAProxy만 있다고 무중단 배포가 자동으로 완성되는 건 아니다.
앱이 안전하게 종료되어야 하고, 헬스체크가 제대로 되어야 하고, DB 마이그레이션도 조심해야 한다.
특히 DB 변경은 생각보다 위험하다.
서버는 한 대씩 교체할 수 있지만, DB 스키마는 보통 같이 쓴다.
새 코드에서는 필요한 컬럼인데 아직 DB에 없거나, 반대로 기존 코드가 쓰는 컬럼을 먼저 지워버리면 배포 중간에 장애가 날 수 있다.
그래서 무중단 배포를 생각하면 애플리케이션 서버만 볼 게 아니라 DB 변경 순서도 같이 봐야 한다.
예를 들면 이런 식이 더 안전하다.
1. 기존 코드와 새 코드가 모두 버틸 수 있게 DB 컬럼 추가
2. 새 코드 배포
3. 데이터가 정상적으로 쌓이는지 확인
4. 더 이상 안 쓰는 컬럼은 나중에 제거이런 걸 생각하지 않고 “HAProxy 붙였으니 무중단 배포 끝”이라고 보면 안 된다.
HAProxy 설정 자체도 처음에는 낯설다.
frontend, backend, server, check, balance 같은 키워드가 계속 나오는데, 대충 보면 설정 파일이 단순해 보여도 실제 운영에서는 하나씩 의미가 있다.
간단히 보면 이렇다.
frontend http_front
bind *:80
default_backend app_backend
backend app_backend
balance roundrobin
option httpchk GET /health
server app01 10.0.0.11:8080 check
server app02 10.0.0.12:8080 checkfrontend는 클라이언트 요청을 받는 입구다.
backend는 실제 요청을 넘길 서버 목록이다.
balance roundrobin은 서버들에 순서대로 요청을 나눠주는 방식이다.
server app01 ... check는 app01 서버를 등록하고 헬스체크 대상으로 삼겠다는 의미다.
이 정도만 봐도 기본적인 로드밸런싱은 이해할 수 있다.
하지만 무중단 배포까지 생각하면 서버를 언제 빼고, 언제 다시 넣고, 실패했을 때 어떻게 롤백할지까지 이어서 봐야 한다.
실제로 배포 흐름을 잡는다면 이런 식으로 정리할 수 있다.
app-01 배포
1. HAProxy에서 app-01 신규 트래픽 제외
2. app-01의 기존 요청 처리 대기
3. app-01 애플리케이션 종료
4. 새 버전 배포
5. app-01 실행
6. /health 정상 확인
7. HAProxy에 app-01 다시 포함그다음 app-02도 같은 방식으로 진행한다.
이 과정에서 로그도 같이 봐야 한다.
HAProxy 통계 화면이나 서버 로그를 보면서 실제로 트래픽이 빠졌는지, 특정 서버에 요청이 몰리지 않는지, 5xx가 튀지 않는지 확인하는 게 좋다.
무중단 배포는 이름만 보면 뭔가 대단한 기술처럼 느껴지지만, 결국 핵심은 순서다.
요청을 받을 서버를 남겨둔 상태에서 하나씩 교체한다.
문제가 있는 서버에는 요청을 보내지 않는다.
새 서버가 정상인지 확인한 뒤 다시 트래픽을 보낸다.
기존 요청은 가능하면 끊지 않고 마무리한다.
이 네 가지가 잘 맞아야 한다.
HAProxy는 이 흐름을 만들기 좋은 도구다.
로드밸런싱, 헬스체크, 서버 제외, 트래픽 전환 같은 기능을 조합하면 단순한 구조에서도 무중단 배포에 가까운 운영을 만들 수 있다.
다만 HAProxy를 붙였다고 끝나는 건 아니었다.
애플리케이션의 graceful shutdown, 헬스체크 설계, DB 변경 순서, 롤백 방법까지 같이 봐야 했다.
처음에는 단순히 “서버 앞에 프록시 하나 두는 것” 정도로 생각했는데, 실제로는 배포 흐름 전체를 정리하게 만드는 도구에 가까웠다.
그래서 HAProxy를 공부할 때는 설정 문법만 보는 것보다, 배포 중에 요청이 어떻게 흐르는지 같이 그려보는 게 훨씬 이해가 잘 됐다.
사용자 요청
|
HAProxy
|
정상 서버로만 전달
|
배포 중인 서버는 잠시 제외
|
정상 확인 후 다시 포함이 흐름이 머릿속에 들어오면 무중단 배포도 조금 덜 어렵게 느껴진다.
'Infra' 카테고리의 다른 글
| RabbitMQ를 이해해보자, Exchange와 Queue가 헷갈렸던 이유 (2) (0) | 2026.05.09 |
|---|---|
| RabbitMQ를 이해해보자, 메시지 큐를 왜 쓰는 걸까? (1) (0) | 2026.05.09 |
| 리눅스 netstat과 ss 차이 (0) | 2026.05.06 |
| Redis Sentinel 정리, Failover와 Redis Cluster 차이 이해하기 (2) (0) | 2026.05.04 |
| Redis Sentinel 정리, Master 장애를 자동으로 복구하는 구조 이해하기 (1) (0) | 2026.05.04 |
 RabbitMQ를 이해해보자, Exchange와 Queue가 헷갈렸던 이유 (2)
RabbitMQ를 이해해보자, Exchange와 Queue가 헷갈렸던 이유 (2)
 RabbitMQ를 이해해보자, 메시지 큐를 왜 쓰는 걸까? (1)
RabbitMQ를 이해해보자, 메시지 큐를 왜 쓰는 걸까? (1)
 리눅스 netstat과 ss 차이
리눅스 netstat과 ss 차이
 Redis Sentinel 정리, Failover와 Redis Cluster 차이 이해하기 (2)
Redis Sentinel 정리, Failover와 Redis Cluster 차이 이해하기 (2)